
*better: More thorough, more relevant, more effective.
...more Alerts, more All Clears, more details, more control in your hands.
|
|
Foxhound is the better* Database Monitor for SQL Anywhere.
*better: More thorough, more relevant, more effective.
...more Alerts, more All Clears, more details, more control in your hands.
|
Breck Carter
Last modified: October 6, 1997
mail to: bcarter@bcarter.com
Should I use business columns as primary key fields for tables in the database, or generate artificial primary key values?
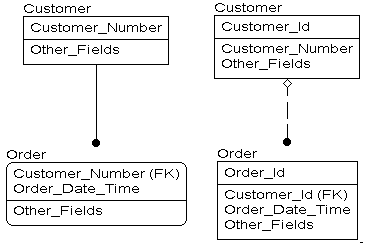
When business-related columns are used as primary keys they are often called intelligent or natural keys. For example, if the user gives each customer a unique customer number that value might naturally serve as the primary key for the customer table.
A child table called order might have an intelligent primary key consisting of two columns: customer_number to act as a foreign key pointer to the customer table plus order_date_time to identify different orders for one customer.
An alternative is to use system-generated artificial primary key values. These are often called surrogate keys because they are replacements for the intelligent keys, or blind keys because the user doesn't see them.
In the example above, the primary key to customer would be a surrogate customer_id column whose value would be set to 1, 2, 3 as new rows are inserted. The customer_number column would still be included in the table, with a unique index, but it would not be part of the primary key.
The primary key to the order table would now consist of a single surrogate order_id column. The customer_id column would be included as a foreign key pointer to the parent table but would not be part of the primary key. Order_date_time would also be included but it too would be an ordinary data field. The customer_number column would be dropped from the order table.
Figure 1 shows what the two alternatives look like. In this example, the surrogate key solution adds two columns to the database. In most databases, however, the number of columns actually drops when surrogate keys are used because multi-column intelligent foreign keys are replaced with single-column surrogate foreign keys.
Besides the fact that Chris Date likes surrogate keys and Joe Celko likes intelligent keys, each alternative has a number of real-world advantages and disadvantages.
The biggest disadvantage for intelligent keys, and a corresponding advantage for surrogate keys, is that primary keys are hard to change. Whenever a primary key changes in value, or columns are added to or dropped from a primary key, the effects cascade down through foreign key relationships.
Intelligent keys suffer from this problem because not only are they used as primary and foreign keys but they also have some business meaning associated with them. When the business changes, so do the primary key values or structure, with all the problems associated with such a change.
Surrogate primary keys avoid this problem because they never need changing. The user assigns no business meaning to a surrogate key so neither its values nor its structure needs to be changed when the business changes. The business columns that used to be part of an intelligent primary key are now simple data columns that can be changed at will and even added or dropped with relative ease. Uniqueness of the business column values can still be guaranteed by using a secondary index.
The biggest advantage for intelligent keys is that users understand what they mean whereas surrogate keys don't make any business sense. Custom applications can hide surrogate keys from the end user but adhoc database tools cannot: The user must learn what these columns are and how to use them to code joins.
In many cases adhoc queries using surrogate keys actually require more joins because fewer columns are cascaded from table to table. For example, a query that selects all customer_number and order_date_time values needs to join the customer and order tables when surrogate keys are used. With intelligent keys everything can be found in the order table.
The situation is even worse if the user is allowed to insert new rows using adhoc tools. Not only is an understanding of surrogate key columns required but new values must somehow be generated.
Other advantages and disadvantages aren't quite so profound but can be very important in some situations.
Performance may differ between the two techniques. A single-column surrogate key may be faster than a multi-column intelligent key. On the other hand, a simple incrementing surrogate key may cause index contention problems not found with a randomly distributed intelligent key.
When surrogate primary keys are used extra indexes may be required on the business columns that used to be part of the intelligent primary key. These indexes may be necessary to preserve uniqueness and satisfy queries, and they may make updates slower. Of course, anything that forces us think carefully about index design is a good thing; as Jim Panttaja says, using a clustered index for the primary key is usually not the best choice.
Coding SQL select statements is certainly different between the two techniques. On one hand, it's easier to join tables with surrogate keys because only single columns are involved. On the other hand, it was noted earlier that surrogate keys may increase the number of joins because business columns from parent tables are not repeated in child tables.
In other words, there may be fewer joins when intelligent keys are used but they are harder to code because they involve more columns. This becomes quite apparent with drop-down DataWindows where a single-column surrogate key is much easier to work with than a multi-column intelligent key (See also: Multi-Key DropDownDataWindows).
Sometimes an artificial or surrogate key actually makes sense from a business point of view. This is true whenever a true intelligent primary key does not exist, or whenever partial data must be captured and saved before the complete intelligent key is known.
Choosing to use a surrogate key is not an easy decision to make. If you do so, you are immediately faced with the task of generating values. Some databases provide an "auto incrementing" or "identity" feature for this purpose. This feature works OK for single table inserts but isn't very popular when a whole hierarchy of parent-child rows must be inserted in one business transaction.
If your database is updated by only one user, the simple statement select max ( customer_id ) + 1 from customer will provide a valid next value to use. However, if more than one user can update the database this technique does not guarantee uniqueness because two users could obtain the same result from the select.
A do-it-yourself solution involves the use of a "Surrogate Id" table to hold the next value for each surrogate primary key in the database, and a function that returns new key values and keeps the Surrogate Id table up to date. Figure 2 shows what the table looks like.

The surrogate_id table is quite simple. It has an intelligent primary key consisting of the table and column names for each surrogate primary key in the database, and one data column to hold the next value for that surrogate key: 1, 2, 3, etc.
At first glance the use of surrogate_id to determine the next key value also seems simple. All one must do is select the next value and then update it for later use, correct?
Not quite: That approach isn't much better than the select max solution because it would still allow two users to select the same next value in a multi-user scenario.
Other challenges include: